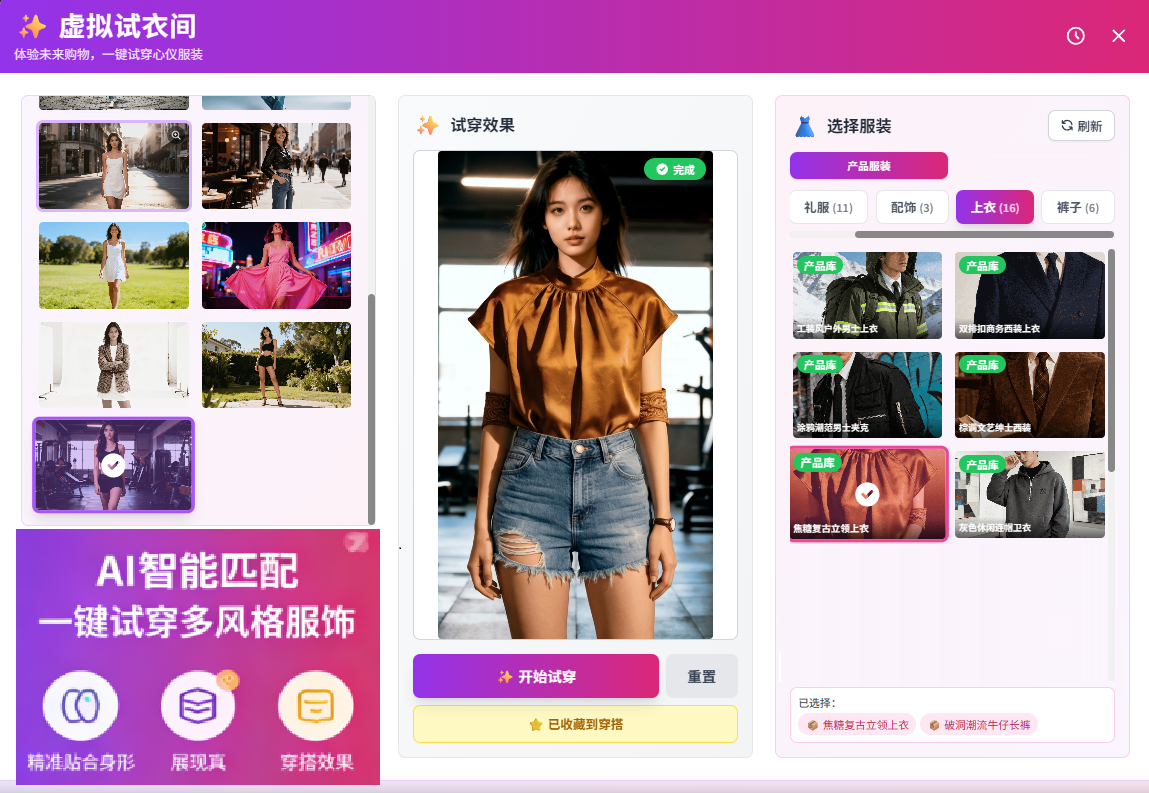
你只需要上传一张照片,30 秒后就能看到自己穿着某件衣服的效果——这背后,藏着相当精密的 AI 技术。 本文用通俗的语言,为你揭开 AI 虚拟试衣的技术原理。
为什么 AI 虚拟试衣很难?
在 AI 技术成熟之前,虚拟试衣一直是个难题。主要挑战有三个:
- 服装形变复杂:衣服穿在不同体型、不同姿势的人身上,形状会发生巨大变化,特别是褶皱、垂感、面料弹性都不一样
- 人体遮挡问题:手臂、腰部等区域如何让衣服"正确地"盖在人体上,涉及精确的遮挡关系计算
- 细节保真:衣服上的图案、纹理、颜色要保持高度一致,不能在生成过程中失真
传统方法用 3D 建模,精度高但成本极高,普通消费者无法使用。 现在 AI 虚拟试衣用的是基于扩散模型(Diffusion Model)的深度学习方案,效果好、速度快、成本低。
核心技术一:人体姿态估计
AI 要把衣服"穿"到你身上,第一步是理解你的身体结构。这依赖人体姿态估计(Human Pose Estimation)技术:
- AI 分析你上传的照片,识别出 17-18 个关键身体关节点(肩膀、肘部、腰部、臀部等)
- 根据关节点构建人体骨架,准确判断你的身体姿势和朝向
- 估算你的体型比例,为后续衣服形变提供基础数据
这一步是所有后续处理的基础。估计不准,衣服就会"飘"在身体旁边,而不是贴合穿着。
核心技术二:服装解析与特征提取
同时,AI 对你选择的衣服图片进行深度分析:
服装分割
精确提取衣服轮廓,去除背景,识别领口、袖口、下摆等关键区域
纹理特征提取
提取衣服的颜色、图案、纹理细节,确保生成时不失真
类别识别
判断衣服类型(上衣/裙子/外套等),为后续形变估算提供依据
核心技术三:扩散模型图像生成
这是最关键的一步。现代 AI 试衣使用基于 Stable Diffusion 或类似架构的条件扩散模型来生成穿着效果图。
简单来说,扩散模型的工作流程是:
- 第一步:把目标图(有噪声的初始状态)逐步去噪,生成新图像
- 条件控制:同时将"人体姿态信息"和"衣服特征"作为条件,引导生成方向
- 迭代细化:经过多次迭代,AI 不断优化衣服与人体的贴合效果
- 细节修复:对生成图中的边缘、褶皱、阴影进行细化处理,提升真实感
扩散模型的强大之处在于,它不是简单地"贴上去",而是真正理解了服装在特定体型和姿势下应该呈现的形态,并重新生成一张全新的图像。
为什么能在 30 秒内完成?
扩散模型本身计算量很大,早期需要几分钟。现在能做到 30-95 秒,得益于几项优化:
- GPU 加速推理:服务器端使用高性能 GPU 集群,大幅加速计算
- 模型蒸馏:将大模型知识迁移到更轻量的模型,不牺牲质量的前提下提升速度
- 采样步数优化:使用 DDIM、DPM-Solver++ 等快速采样算法,减少所需步数
- 异步处理架构:用户提交任务后异步处理,多个请求并发执行,不互相阻塞
技术的局限性
AI 虚拟试衣已经非常成熟,但仍有一些局限值得了解:
- 极端姿势效果较差:侧身、后背等非正面姿势,生成效果不如正面照稳定
- 透明/半透明面料:薄纱、蕾丝等特殊面料的透视效果模拟难度大
- 配饰未包含:帽子、围巾等配件通常不在试衣范围内
- 尺码感知有限:目前 AI 主要模拟外观效果,对合身程度的判断不够精准
这些局限正在随着技术迭代不断改善。幻衣阁持续引入最新的 AI 试衣模型,让生成效果越来越真实。
幻衣阁的技术选型
幻衣阁整合了多个业界领先的 AI 试衣模型,用户可以根据需要选择:
Nano Banana
30秒出图,适合快速预览,日常穿搭参考
Nano Banana Pro
95秒出图,细节更精致,适合正式决策参考
Apollo AI
不同风格模型,适合特定服装类型的试穿
相关文章